ZDREAM - Thassarian 的个人博客
对抗变化的方法唯有拥抱变化。
目 录CONTENT
以下是
数据分析
相关的文章
-
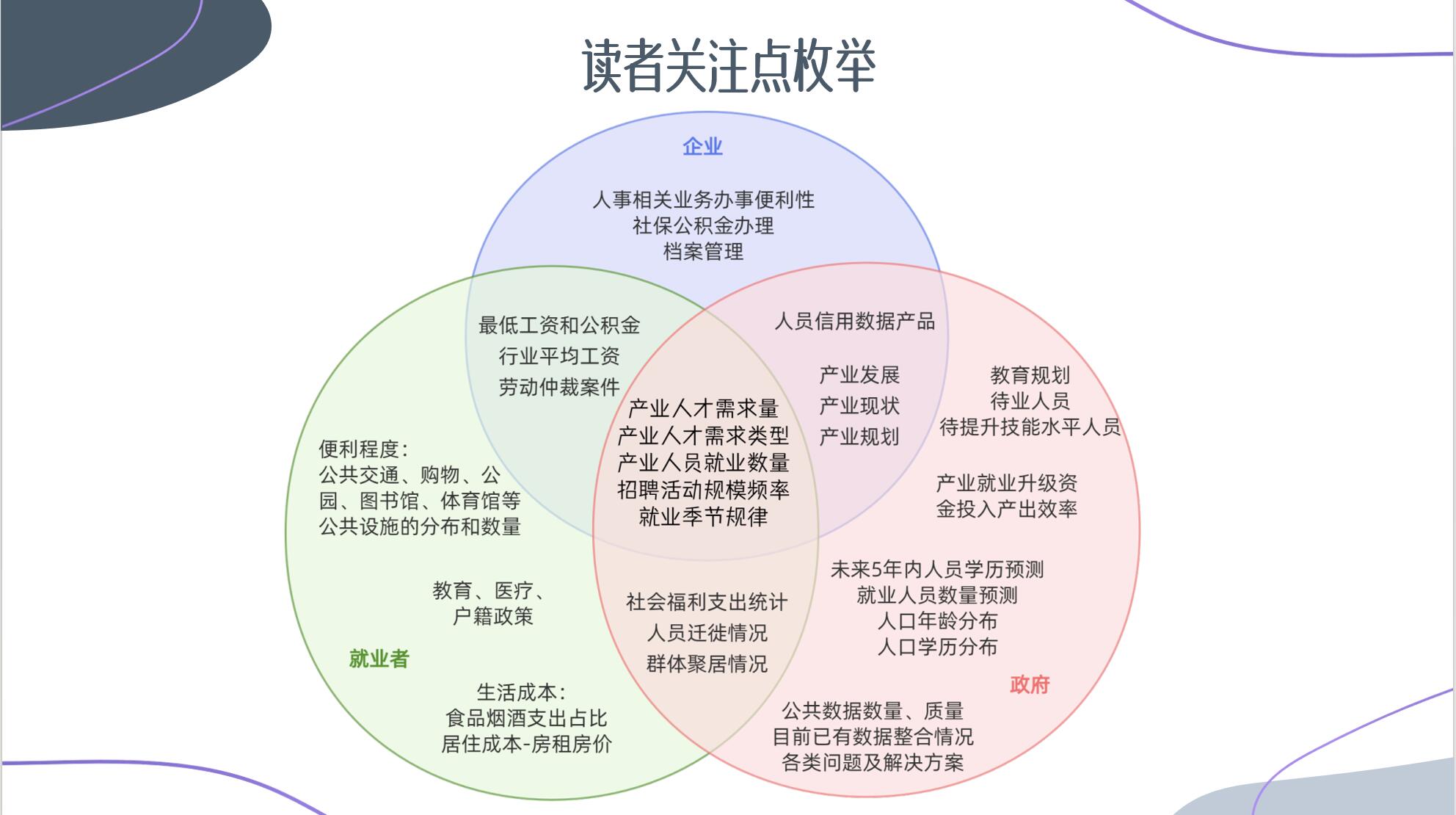
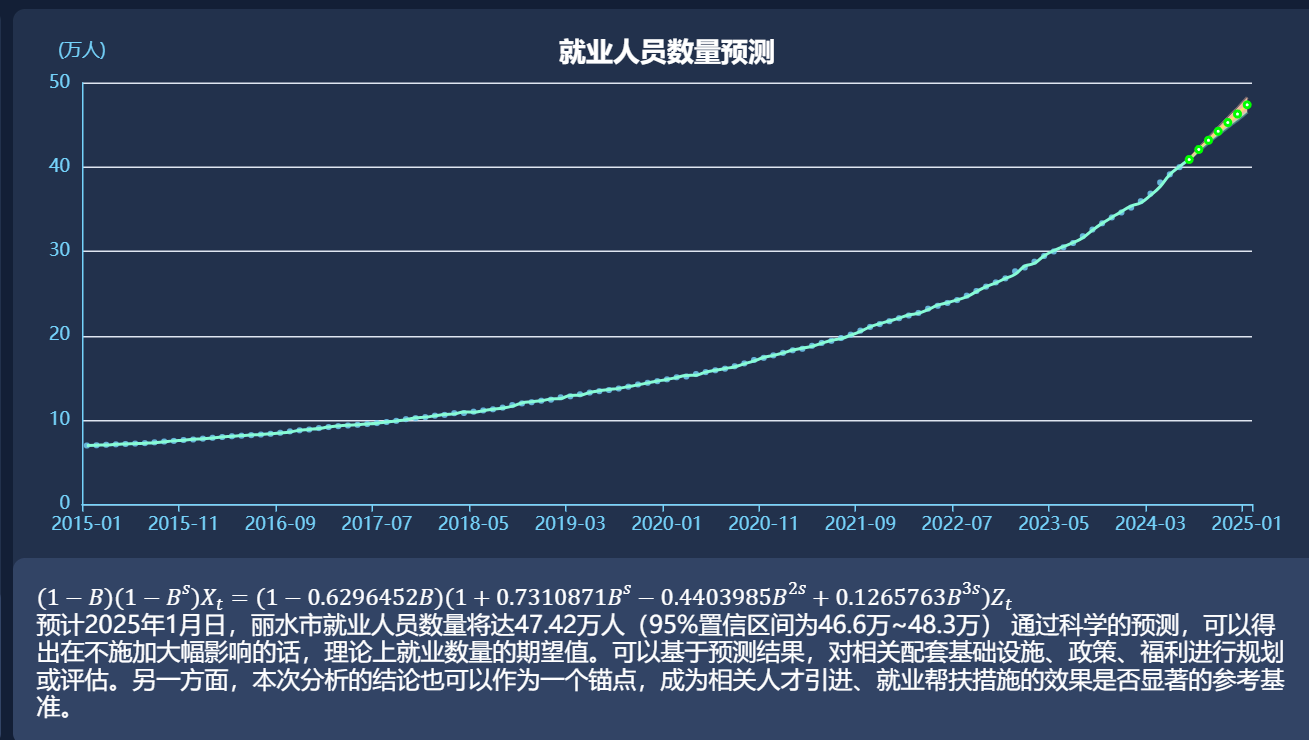
 XX市人才相关公共数据统计分析报告 本文现所展示的全统计基准数据均来自市统计局年鉴及国家统计局发布在互联网的公开数据。摘要:(待全部统计完成后完善)市数据局已完成大量人才相关公告数据的归集工作,建有人才地图、青年留存等专题,涉及近百个目录、4.8亿条数据,数据面广,种类繁多,更新及时,数据规范,格式统一,数据质量较好,但数据的全面程度尚需确认,数据间的缺少明确的关联汇总、分析结论类数据量较少。XX市总体就业情况呈增长态势,但各项细节指标不容乐观。XX市人才相关公共数据统计分析报告前言参考地市(选择理由)分项统计就业人口年龄分布人口结构数据展示形式基础统计人员迁入人员迁出就业人员数量变化季节性规律数据模型拟合以及预测人才保障工作工资水平统计社会福利支出统计组织招工活动(待统计)一老一小可支配收入比(待统计)人才需求(待统计)人才学历分布(待统计)现有人才学历分类统计高学历人才流失情况未来5年内人员学历预测人才产业结构(已统计待总结)人才公共数据评价(待细化)下一步工作团队计划推荐数据运维团队参与推进应用参考报告:前言我们深知人才工作的复杂性,对人才数据的分析与评价是无法脱离诸如“人口结构、就业状况、产业布局、教育水平、金融水平”等各类经济和民生指标而单独进行的。本次统计分析作为一项探索性工作,缺乏与相关业务部门之间的沟通调研,故更多的是起到抛砖引玉的作用,以期引发更深入的讨论与研究。未来我们将积极走访业务部门,挖掘相关统计分析需求,争取从更全面、更专业的视角出发,参考更多精准的数据,进行更为深入、准确的分析工作,为部门业务提供数据赋能,为决策提供强有力的数据支持。双重视角:用工/就业参考地市(选择理由)除了参考全省均值、将XX市各区县进行横向比较外,本次分析还选择了在常住人口、生产总值、产业结构方面与XX市都较为接近的YY市作为同级参考。2022(年末)XX市YY市第一产业产值118 亿元93 亿元第一产业产值占比6.44%4.64%第二产业产值706 亿元874 亿元第二产业产值占比38.56%43.63%第三产业产值1007 亿元1036 亿元第三产业产值占比55.00%51.72%生产总值1831 亿元2003 亿元年末常住人口251.5 万人229 万人人均生产总值72812 元87544 元分项统计就业人口年龄分布人口结构数据展示形式数据可以不准确,概念先列出来,抛砖引玉。内层工龄人口和非工龄人口数量,中层就业人员数量,外层学历情况交叉统计各学历未就业人员数量。就业吸引力评分。实际人口流动情况统计。预期收入不同产业人数与工资(从业人数top5)人员聚居情况环境-空气质量、交通覆盖案件、事件总数量每百人事件数量生活成本食品烟酒居住教育医疗基础统计通过对就业人口年龄分布进行统计,不难看出XX就业人员老龄化情况颇为严重。26岁以下就业人员方面,全省平均占比为15.02%,YY市占比为XX,XX则仅有8.66%。LD区是全市唯一的年轻人(18岁以下人口)数量在正向增加的区县。XX市处在26~45岁之间就业人员占比为64.55%,与全省66.21%水平相近。全省45岁以上就业人员占比为18.77%,而XX则高达26.79%。年龄段全省比例YY市比例XX市比例XX市人数26以下15.02%8.66%2044226到3017.18%13.97%3297231到3517.98%16.77%3957736到4017.94%18.24%4304541到4513.11%15.55%3669845到509.78%14.12%3331950以上8.99%12.67%29886常住人口方面,SX县的人口老龄化是XX市最严重的,60岁以上人口已超过25%,而且也是老龄人口增速最快的区县,2015年~2022年期间60岁以上人口比例增加了5.43%。虽说XX作为全国唯一的地级市“中国长寿之乡”,存在相关养老产业聚集、吸引了更多老龄人口留存的情况,但也要及时正视就业人口老龄化问题,否则这个情况将不仅影响本地劳动力市场的活力,也对城市的可持续发展带来了潜在挑战。人员迁入浙江省作为经济发达省份,对外来人员的吸纳程度较高,其就业人员的来源呈现出多元化的特点。据统计,浙江省79%的就业人员原始户籍来自其他省份、港澳台及国外等地。但XX市的就业人员来源则相对集中。数据显示,XX市的就业人员中,本省占比达到65.44%,本市占比更是高达58.22%。在XX市外来人员占比超过3%的省份依次是贵州省、河南省、江西省、四川省和湖北省。省份数量占比浙江省15441265.44%贵州省93373.96%河南省90293.83%江西省80433.41%四川省79163.36%湖北省73933.13%XX市相比浙江平均水平来说,对外来人员的吸引力相对较低,但仍然有1/3的劳动力是外来流入,且主要来源于邻近的省份。了解和关注主要的外来劳动力来源地,有助于制定更为精准的人才引进策略。人员迁出人员迁出率前三的依次是QY县(7.05‰)、YH县(6.58‰)、JN县(6.55‰)全市迁入迁出相抵之后,唯一正向流入的区县是莲都区。XX全市迁入人数迁出人数迁出率2014年23489181662015年15570133500.501%2016年11463108290.404%2017年12528146430.544%2018年11906165800.614%2019年10853162530.600%2020年9056148540.549%2021年8624160910.596%2022年8361118340.439%就业人员数量变化季节性规律俗语说“金三银四,金九银十”,这一经验之谈在本次统计中得到了充分印证。通过图形化展现XX就业人员的每年每月增量数据,不难发现每年人员就业呈现出明显的季节性变化,高峰确实是三月和九月。从二月开始,就业人数快速上升,三月即达顶峰;随后逐渐下降,六月左右达到低谷。接着,从七月开始逐渐回升,再次在九月达到另一个高峰。十月之后,就业人数开始大幅减少,并在接下来的几个月内维持在一个较低但相对稳定的水平,直到次年的二月再次开始回升。建议顺应就业市场自身季节性变化的特点,在就业高峰阶段(如三月和九月)集中开展人才引进、供需协调对口等活动,在淡季期间则着重宣传帮扶或培训教育等人才储备工作。数据模型拟合以及预测XX市就业人员的“年度新增数量”缓步升高,月度新增数据波动明显(参考上节),难以利用。但将月度数据累积聚合之后,总的就业人员数量则明显呈加速上扬的线性变化,趋势接近二次函数,具备回归分析的可能性。基于年度累积数据,进行二次函数模型的初步拟合:本次拟合虽然总体接近,但具体到每个时间点时差异依然较大。结合季节变化特点进行基于时间变量的序列分析:通过对原始数据进行细化拆分、同时结合数据的季节性特点,完成时间序列分析式模型优化。结合季节波动规律后的数据模型拟合度极高,预测数据很有参考价值。预计2025年1月日,XX市就业人员数量将达47.42万人(95%置信区间为46.6万~48.3万)。*由于前期数据核验过程中未及时发现同一个就业人员可能有多条就业登记记录(可能是因为就业人员存在跳槽),导致待分析数据量与实际情况有差异、预测结果不准确,待修正。通过科学的预测,可以得出在不施加大幅影响的话,理论上就业数量的期望值。一方面可以基于预测结果,对相关配套基础设施、政策、福利进行规划或评估。另一方面,本次分析的结论也可以作为一个锚点,成为相关人才引进、就业帮扶措施的效果是否显著的参考基准。比如说在当前的政策和环境条件下,原本2025年7月1日是就业人数期望是万人。假设实际就业人员超出该预测值,甚至超过原本的95%置信区间上限,就说明本地的人才措施成效相当显著。*可再次细分数据,分别针对各区县进行建模和预测。人才保障工作聚才留才,要千方百计、用心用情。全面落实好人才保障工作,需要围绕薪资待遇、衣食住行、一老一小、社会福利等各个方面解决好人才落地的后顾之忧,让人才心无旁骛“安营扎寨”,全力以赴“施展拳脚”。已知措施类型:通过财政、货币等宏观调控政策来熨平经济周期,解决周期性失业。组织开展求职招聘服务提高人岗匹配效率加强职业技能培训破除劳动力自由流动障碍工资水平统计截止2022年末,XX市城镇常住居民工资性收入平均为28874元。2019年之前,年均涨幅约10%,新冠元年之后,2020年度薪资涨幅降至5.25%,2021年涨幅绝对值恢复至疫情之前水平,2022年增速再度降低,仅有3.41%。工资性收入金额差值幅度2014年154222015年17010158810.30%2016年18719170910.05%2017年2039916808.97%2018年2240820099.85%2019年2455421469.58%2020年2584412905.25%2021年2792120778.04%2022年288749533.41%社会福利支出统计针对[社会保障和就业]预算内支出金额、财政支出占比进行了统计和分析。正在进一步结合“就业人员跟随产业结构变更收益”,在“假设财政支出与产业人员结构变更存在强相关性”的情前提下,尝试从数据角度去评价各区县财政支出与收益成效比,比较资金利用效率更高的区县是哪个,进而针对性分析该地区是否存在值得推广学习的经验。组织招工活动(待统计)积极组织招聘活动,频率、规模一老一小低保救助相关落实情况统计可支配收入比(待统计)目录:XX市分县城镇居民人均可支配收入信息、XX市分县农民居民人均可支配收入信息即“衣食住行”保障问题-房价高已采取措施-碧湖新城(但涉及耕地红线)松阳问题人才需求(待统计)招聘职位情况(有目录):岗位数量、薪资金额企业数量(已统计待解读)产业类型预测未来劳动力市场的需求和变化。统计结构性失业人才学历分布(待统计)现有人才学历分类统计初中人数,高中人数,职高、专科、本科、研究生、博士高学历人才流失情况重点参考《青年留存》专题库相关分析数据大学毕业生就业数据中,本地就业率待统计未来5年内人员学历预测结合当前学生信息、升学率、就业率等数据开展建模与预测人才产业结构(已统计待总结)基准理论:三次产业变动的配第-克拉克定理:一阶段:第一产业比重逐渐下降,第二产业比重上升二阶段:第三产业比重上升不考核生产总值,但是因地制宜,发展最适合的,产值效率更好的产业。本次分析工作中尝试结合产业类型、生产总值、就业人员数量、产业就业人员变化量等数据建立算法,计算就业人员跟随产业结构变更后的收益。人才公共数据评价(待细化)市数据局已完成大量人才相关公告数据的归集工作,数据涉及面广,种类繁多,缺乏汇总。更新及时,数据规范,格式统一,数据质量较好,但数据的全面程度尚需确认。下一步工作团队计划取数数据链路固化,数据自动更新。最新数据通过数据局批量数据及时更新,完善数据治理、构建固定的统计分析流程,实现相关指标数据的自动更新。提升业务变化感知度,加强数据可靠性,降低重复性工作的精力浪费。报表报告网页化,并提供嵌入到其他站点的能力。开发产业区、产值、就业安置量、人才需求,地图3D标注,人才热力图。开展针对创新型、创业型人才的发掘。聚焦五大主导产业人才需求供给情况。XX近些年开始强调“工业强市”,加快培育半导体全链条、精密制造、健康医药、时尚产业、数字经济五大主导产业集群。推进覆盖面更广、更深入的【营商环境分析】立项工作。推荐数据运维团队参与推进应用在校大学生专业(odps)与当前XX产业情况比较开发专业人才搭线相关数据产品未来人口年龄分布(不需要通过拟合预测,直接使用当前人口信息,综合迁入迁出率和死亡率统计即可)。服务可及性档案管理职业教育实训实习基地教育人才成人教育不同类型学校数量、容量学生存量小语种国际贸易专业与就业之间的差异关系办事便利性社保公积金办理便捷情况人才监管框架治安劳动仲裁案件,人员相关信用数据产品信息。
XX市人才相关公共数据统计分析报告 本文现所展示的全统计基准数据均来自市统计局年鉴及国家统计局发布在互联网的公开数据。摘要:(待全部统计完成后完善)市数据局已完成大量人才相关公告数据的归集工作,建有人才地图、青年留存等专题,涉及近百个目录、4.8亿条数据,数据面广,种类繁多,更新及时,数据规范,格式统一,数据质量较好,但数据的全面程度尚需确认,数据间的缺少明确的关联汇总、分析结论类数据量较少。XX市总体就业情况呈增长态势,但各项细节指标不容乐观。XX市人才相关公共数据统计分析报告前言参考地市(选择理由)分项统计就业人口年龄分布人口结构数据展示形式基础统计人员迁入人员迁出就业人员数量变化季节性规律数据模型拟合以及预测人才保障工作工资水平统计社会福利支出统计组织招工活动(待统计)一老一小可支配收入比(待统计)人才需求(待统计)人才学历分布(待统计)现有人才学历分类统计高学历人才流失情况未来5年内人员学历预测人才产业结构(已统计待总结)人才公共数据评价(待细化)下一步工作团队计划推荐数据运维团队参与推进应用参考报告:前言我们深知人才工作的复杂性,对人才数据的分析与评价是无法脱离诸如“人口结构、就业状况、产业布局、教育水平、金融水平”等各类经济和民生指标而单独进行的。本次统计分析作为一项探索性工作,缺乏与相关业务部门之间的沟通调研,故更多的是起到抛砖引玉的作用,以期引发更深入的讨论与研究。未来我们将积极走访业务部门,挖掘相关统计分析需求,争取从更全面、更专业的视角出发,参考更多精准的数据,进行更为深入、准确的分析工作,为部门业务提供数据赋能,为决策提供强有力的数据支持。双重视角:用工/就业参考地市(选择理由)除了参考全省均值、将XX市各区县进行横向比较外,本次分析还选择了在常住人口、生产总值、产业结构方面与XX市都较为接近的YY市作为同级参考。2022(年末)XX市YY市第一产业产值118 亿元93 亿元第一产业产值占比6.44%4.64%第二产业产值706 亿元874 亿元第二产业产值占比38.56%43.63%第三产业产值1007 亿元1036 亿元第三产业产值占比55.00%51.72%生产总值1831 亿元2003 亿元年末常住人口251.5 万人229 万人人均生产总值72812 元87544 元分项统计就业人口年龄分布人口结构数据展示形式数据可以不准确,概念先列出来,抛砖引玉。内层工龄人口和非工龄人口数量,中层就业人员数量,外层学历情况交叉统计各学历未就业人员数量。就业吸引力评分。实际人口流动情况统计。预期收入不同产业人数与工资(从业人数top5)人员聚居情况环境-空气质量、交通覆盖案件、事件总数量每百人事件数量生活成本食品烟酒居住教育医疗基础统计通过对就业人口年龄分布进行统计,不难看出XX就业人员老龄化情况颇为严重。26岁以下就业人员方面,全省平均占比为15.02%,YY市占比为XX,XX则仅有8.66%。LD区是全市唯一的年轻人(18岁以下人口)数量在正向增加的区县。XX市处在26~45岁之间就业人员占比为64.55%,与全省66.21%水平相近。全省45岁以上就业人员占比为18.77%,而XX则高达26.79%。年龄段全省比例YY市比例XX市比例XX市人数26以下15.02%8.66%2044226到3017.18%13.97%3297231到3517.98%16.77%3957736到4017.94%18.24%4304541到4513.11%15.55%3669845到509.78%14.12%3331950以上8.99%12.67%29886常住人口方面,SX县的人口老龄化是XX市最严重的,60岁以上人口已超过25%,而且也是老龄人口增速最快的区县,2015年~2022年期间60岁以上人口比例增加了5.43%。虽说XX作为全国唯一的地级市“中国长寿之乡”,存在相关养老产业聚集、吸引了更多老龄人口留存的情况,但也要及时正视就业人口老龄化问题,否则这个情况将不仅影响本地劳动力市场的活力,也对城市的可持续发展带来了潜在挑战。人员迁入浙江省作为经济发达省份,对外来人员的吸纳程度较高,其就业人员的来源呈现出多元化的特点。据统计,浙江省79%的就业人员原始户籍来自其他省份、港澳台及国外等地。但XX市的就业人员来源则相对集中。数据显示,XX市的就业人员中,本省占比达到65.44%,本市占比更是高达58.22%。在XX市外来人员占比超过3%的省份依次是贵州省、河南省、江西省、四川省和湖北省。省份数量占比浙江省15441265.44%贵州省93373.96%河南省90293.83%江西省80433.41%四川省79163.36%湖北省73933.13%XX市相比浙江平均水平来说,对外来人员的吸引力相对较低,但仍然有1/3的劳动力是外来流入,且主要来源于邻近的省份。了解和关注主要的外来劳动力来源地,有助于制定更为精准的人才引进策略。人员迁出人员迁出率前三的依次是QY县(7.05‰)、YH县(6.58‰)、JN县(6.55‰)全市迁入迁出相抵之后,唯一正向流入的区县是莲都区。XX全市迁入人数迁出人数迁出率2014年23489181662015年15570133500.501%2016年11463108290.404%2017年12528146430.544%2018年11906165800.614%2019年10853162530.600%2020年9056148540.549%2021年8624160910.596%2022年8361118340.439%就业人员数量变化季节性规律俗语说“金三银四,金九银十”,这一经验之谈在本次统计中得到了充分印证。通过图形化展现XX就业人员的每年每月增量数据,不难发现每年人员就业呈现出明显的季节性变化,高峰确实是三月和九月。从二月开始,就业人数快速上升,三月即达顶峰;随后逐渐下降,六月左右达到低谷。接着,从七月开始逐渐回升,再次在九月达到另一个高峰。十月之后,就业人数开始大幅减少,并在接下来的几个月内维持在一个较低但相对稳定的水平,直到次年的二月再次开始回升。建议顺应就业市场自身季节性变化的特点,在就业高峰阶段(如三月和九月)集中开展人才引进、供需协调对口等活动,在淡季期间则着重宣传帮扶或培训教育等人才储备工作。数据模型拟合以及预测XX市就业人员的“年度新增数量”缓步升高,月度新增数据波动明显(参考上节),难以利用。但将月度数据累积聚合之后,总的就业人员数量则明显呈加速上扬的线性变化,趋势接近二次函数,具备回归分析的可能性。基于年度累积数据,进行二次函数模型的初步拟合:本次拟合虽然总体接近,但具体到每个时间点时差异依然较大。结合季节变化特点进行基于时间变量的序列分析:通过对原始数据进行细化拆分、同时结合数据的季节性特点,完成时间序列分析式模型优化。结合季节波动规律后的数据模型拟合度极高,预测数据很有参考价值。预计2025年1月日,XX市就业人员数量将达47.42万人(95%置信区间为46.6万~48.3万)。*由于前期数据核验过程中未及时发现同一个就业人员可能有多条就业登记记录(可能是因为就业人员存在跳槽),导致待分析数据量与实际情况有差异、预测结果不准确,待修正。通过科学的预测,可以得出在不施加大幅影响的话,理论上就业数量的期望值。一方面可以基于预测结果,对相关配套基础设施、政策、福利进行规划或评估。另一方面,本次分析的结论也可以作为一个锚点,成为相关人才引进、就业帮扶措施的效果是否显著的参考基准。比如说在当前的政策和环境条件下,原本2025年7月1日是就业人数期望是万人。假设实际就业人员超出该预测值,甚至超过原本的95%置信区间上限,就说明本地的人才措施成效相当显著。*可再次细分数据,分别针对各区县进行建模和预测。人才保障工作聚才留才,要千方百计、用心用情。全面落实好人才保障工作,需要围绕薪资待遇、衣食住行、一老一小、社会福利等各个方面解决好人才落地的后顾之忧,让人才心无旁骛“安营扎寨”,全力以赴“施展拳脚”。已知措施类型:通过财政、货币等宏观调控政策来熨平经济周期,解决周期性失业。组织开展求职招聘服务提高人岗匹配效率加强职业技能培训破除劳动力自由流动障碍工资水平统计截止2022年末,XX市城镇常住居民工资性收入平均为28874元。2019年之前,年均涨幅约10%,新冠元年之后,2020年度薪资涨幅降至5.25%,2021年涨幅绝对值恢复至疫情之前水平,2022年增速再度降低,仅有3.41%。工资性收入金额差值幅度2014年154222015年17010158810.30%2016年18719170910.05%2017年2039916808.97%2018年2240820099.85%2019年2455421469.58%2020年2584412905.25%2021年2792120778.04%2022年288749533.41%社会福利支出统计针对[社会保障和就业]预算内支出金额、财政支出占比进行了统计和分析。正在进一步结合“就业人员跟随产业结构变更收益”,在“假设财政支出与产业人员结构变更存在强相关性”的情前提下,尝试从数据角度去评价各区县财政支出与收益成效比,比较资金利用效率更高的区县是哪个,进而针对性分析该地区是否存在值得推广学习的经验。组织招工活动(待统计)积极组织招聘活动,频率、规模一老一小低保救助相关落实情况统计可支配收入比(待统计)目录:XX市分县城镇居民人均可支配收入信息、XX市分县农民居民人均可支配收入信息即“衣食住行”保障问题-房价高已采取措施-碧湖新城(但涉及耕地红线)松阳问题人才需求(待统计)招聘职位情况(有目录):岗位数量、薪资金额企业数量(已统计待解读)产业类型预测未来劳动力市场的需求和变化。统计结构性失业人才学历分布(待统计)现有人才学历分类统计初中人数,高中人数,职高、专科、本科、研究生、博士高学历人才流失情况重点参考《青年留存》专题库相关分析数据大学毕业生就业数据中,本地就业率待统计未来5年内人员学历预测结合当前学生信息、升学率、就业率等数据开展建模与预测人才产业结构(已统计待总结)基准理论:三次产业变动的配第-克拉克定理:一阶段:第一产业比重逐渐下降,第二产业比重上升二阶段:第三产业比重上升不考核生产总值,但是因地制宜,发展最适合的,产值效率更好的产业。本次分析工作中尝试结合产业类型、生产总值、就业人员数量、产业就业人员变化量等数据建立算法,计算就业人员跟随产业结构变更后的收益。人才公共数据评价(待细化)市数据局已完成大量人才相关公告数据的归集工作,数据涉及面广,种类繁多,缺乏汇总。更新及时,数据规范,格式统一,数据质量较好,但数据的全面程度尚需确认。下一步工作团队计划取数数据链路固化,数据自动更新。最新数据通过数据局批量数据及时更新,完善数据治理、构建固定的统计分析流程,实现相关指标数据的自动更新。提升业务变化感知度,加强数据可靠性,降低重复性工作的精力浪费。报表报告网页化,并提供嵌入到其他站点的能力。开发产业区、产值、就业安置量、人才需求,地图3D标注,人才热力图。开展针对创新型、创业型人才的发掘。聚焦五大主导产业人才需求供给情况。XX近些年开始强调“工业强市”,加快培育半导体全链条、精密制造、健康医药、时尚产业、数字经济五大主导产业集群。推进覆盖面更广、更深入的【营商环境分析】立项工作。推荐数据运维团队参与推进应用在校大学生专业(odps)与当前XX产业情况比较开发专业人才搭线相关数据产品未来人口年龄分布(不需要通过拟合预测,直接使用当前人口信息,综合迁入迁出率和死亡率统计即可)。服务可及性档案管理职业教育实训实习基地教育人才成人教育不同类型学校数量、容量学生存量小语种国际贸易专业与就业之间的差异关系办事便利性社保公积金办理便捷情况人才监管框架治安劳动仲裁案件,人员相关信用数据产品信息。 -
预测未来:基于历史数据的时间序列拟合分析 最终效果在数据处理的日常工作中,我们常常会面对历史数据,并期望能从中洞察未来的趋势。无论是业务量的变化、用户增长的预测,还是像特定领域人才流动的预判,其核心都是一个基于时间的序列。这篇笔记整理了过去一次探索性的尝试,即如何利用R语言对时间序列数据进行拟合与预测,整个过程本身比最终的结论更有记录的价值。 当时设想的场景,是根据过去数年的人才流入数据,来预测未来一段时间的流入趋势。这是一种典型的单变量时间序列分析。核心思路是让机器通过学习历史数据的内在规律——包括长期趋势(Trend)、季节性波动(Seasonal)和随机噪声(Random),来构建一个能够延伸到未来的数学模型。一、数据准备与加载 一切分析始于数据。首先需要将原始数据加载到R环境中,并转化为时间序列分析专用的格式。原始数据通常包含日期和数值两个关键字段。这里使用了 lubridate 包来高效处理日期格式,并用 ts 函数创建一个时间序列对象,明确告知R数据的观测频率(在这个案例中是按月,即frequency=12)。将数据结构化为 ts 对象,是后续所有分析步骤的标准起点。二、序列分解 拿到一个时间序列后,直接建模往往效果不佳,因为它是一个混合体。将其分解,分别观察长期趋势、季节性规律和随机波动,能更好地理解数据特性。R中的 decompose() 函数可以很方便地完成这项工作,它将序列拆解为三个部分。趋势(Trend):数据在长期内的总体走向,是上升、下降还是保持平稳。季节性(Seasonal):数据在一个固定周期内(如年、季度)呈现的规律性波动。随机项(Random):剔除趋势和季节性后,剩余的、无规律的随机扰动。通过分解图,可以直观地判断该序列是否具有明显的趋势性和季节性,为后续选择模型提供依据。三、模型选择与拟合 时间序列预测最常用的模型之一是ARIMA(自回归积分滑动平均模型)。ARIMA的强大之处在于它能处理多种不同类型的时间序列数据,但其p, d, q三个参数的选择却非常考验经验。 幸运的是,forecast 包中的 auto.arima() 函数极大地简化了这一过程。它会自动测试不同的参数组合,通过AIC(赤池信息准则)或BIC(贝叶斯信息准则)等评估标准,寻找最优的模型。这对于快速验证想法非常友好,避免了在调参上投入过多初期精力。summary 会输出最终选定的ARIMA模型参数和一些关键的统计指标,如对数似然、AIC值等,用于评估模型的优劣。四、预测与可视化 模型构建完成后,就可以用它来生成对未来的预测了。forecast() 函数接收拟合好的模型,并指定需要预测的期数(例如h=12代表预测未来12个月)。它不仅会给出预测值,还会提供置信区间(如80%和95%),这在实际应用中非常重要,因为它量化了预测的不确定性。 最后,将原始数据、模型的拟合数据以及未来的预测数据呈现在一张图上,是评估模型效果和展示成果最直观的方式。ggplot2 提供了强大的自定义绘图功能,能够将结果清晰地可视化。最终的图表会清晰地展示历史数据的轨迹、模型在历史数据上的拟合情况,以及向未来延伸的预测曲线和其置信区间。五、实操及优化记录因为最终目标是要导入到网站中动态显示,所以除了执行分析和plot绘图之外,使之持续加工生成json数据也是重要一环。1.就业人员数量预测ctrl+L 清控制台 # 清空数据 Jan 2025 474219.3 468491.3 479947.2 465459.1 482979.4拟合模型数据导出 # 获取拟合值和时间点 简化之后: # 定义时间序列时间戳到年月的转换函数 jsonlite::write_json(fitted_df[c("年月", "拟合值")], path = "D:/逐梦未来/数据分析/营商环境分析/00.数据分析过程文档/人才分析/r_bench/fitted_data.json", pretty = FALSE)原始数据导出 # 处理原始数据data,格式化日期 jsonlite::write_json(data[c("年_月", "就业人数")], path = "D:/逐梦未来/数据分析/营商环境分析/00.数据分析过程文档/人才分析/r_bench/raw_data.json", pretty = FALSE)换一个方法导出原始数据 # 获取、格式化年月、将年月和原始数据添加到数据框中 jsonlite::write_json(raw_df[c("年月", "原始数据")], path = "D:/逐梦未来/数据分析/营商环境分析/00.数据分析过程文档/人才分析/r_bench/raw_data.json", pretty = FALSE)预测数据导出提取和保存预测数据 # 提取预测点的数据 )上面这部分操作可以合并成以下代码 # 提取、转换、保存数据到数据框 jsonlite::write_json(forecast_df_plus[c("年月", "预测值","下限","上限")], path = "D:/逐梦未来/数据分析/营商环境分析/00.数据分析过程文档/人才分析/r_bench/forecast_data.json", pretty = FALSE)2.目录数据线性回归分析(非时间序列) library(ggplot2) theme(panel.grid.major = element_line(color = "grey", linetype = "dotted")) 3.未采用时间序列分析的错误样例这是某一次试验性分析时输出的结果,没有采用时间序列,单纯使用线性回归进行拟合,可以看到实际上偏离情况还是蛮严重的。 参考plot绘图函数pchpch(plotting character)指定绘制点时使用的符号type"p":表示仅绘制数据点(默认的点图)。"l":表示通过线连接数据点(线图)。"b":同时绘制数据点和线(点线图)。"c":仅绘制线,不显示数据点。"o":同时绘制数据点和线,但线会覆盖在点上(与"b"类似,但线的绘制方式略有不同)。"h":绘制垂直的线段从点到x轴(也叫作悬挂图或针状图)。"s":绘制阶梯图。"n":不绘制任何点和线(通常用于初始化一个图形设备,以便后续添加内容)。