


免责声明:
本次测试数据均来自于互联网公开数据:
最终效果
在数据处理的日常工作中,我们常常会面对历史数据,并期望能从中洞察未来的趋势。无论是业务量的变化、用户增长的预测,还是像特定领域人才流动的预判,其核心都是一个基于时间的序列。这篇笔记整理了过去一次探索性的尝试,即如何利用R语言对时间序列数据进行拟合与预测,整个过程本身比最终的结论更有记录的价值。
当时设想的场景,是根据过去数年的人才流入数据,来预测未来一段时间的流入趋势。这是一种典型的单变量时间序列分析。核心思路是让机器通过学习历史数据的内在规律——包括长期趋势(Trend)、季节性波动(Seasonal)和随机噪声(Random),来构建一个能够延伸到未来的数学模型。
一、数据准备与加载
一切分析始于数据。首先需要将原始数据加载到R环境中,并转化为时间序列分析专用的格式。原始数据通常包含日期和数值两个关键字段。这里使用了 lubridate 包来高效处理日期格式,并用 ts 函数创建一个时间序列对象,明确告知R数据的观测频率(在这个案例中是按月,即frequency=12)。
将数据结构化为 ts 对象,是后续所有分析步骤的标准起点。
二、序列分解
拿到一个时间序列后,直接建模往往效果不佳,因为它是一个混合体。将其分解,分别观察长期趋势、季节性规律和随机波动,能更好地理解数据特性。R中的 decompose() 函数可以很方便地完成这项工作,它将序列拆解为三个部分。
趋势(Trend):数据在长期内的总体走向,是上升、下降还是保持平稳。
季节性(Seasonal):数据在一个固定周期内(如年、季度)呈现的规律性波动。
随机项(Random):剔除趋势和季节性后,剩余的、无规律的随机扰动。
通过分解图,可以直观地判断该序列是否具有明显的趋势性和季节性,为后续选择模型提供依据。
三、模型选择与拟合
时间序列预测最常用的模型之一是ARIMA(自回归积分滑动平均模型)。ARIMA的强大之处在于它能处理多种不同类型的时间序列数据,但其p, d, q三个参数的选择却非常考验经验。
幸运的是,forecast 包中的 auto.arima() 函数极大地简化了这一过程。它会自动测试不同的参数组合,通过AIC(赤池信息准则)或BIC(贝叶斯信息准则)等评估标准,寻找最优的模型。这对于快速验证想法非常友好,避免了在调参上投入过多初期精力。
summary 会输出最终选定的ARIMA模型参数和一些关键的统计指标,如对数似然、AIC值等,用于评估模型的优劣。
四、预测与可视化
模型构建完成后,就可以用它来生成对未来的预测了。forecast() 函数接收拟合好的模型,并指定需要预测的期数(例如h=12代表预测未来12个月)。它不仅会给出预测值,还会提供置信区间(如80%和95%),这在实际应用中非常重要,因为它量化了预测的不确定性。
最后,将原始数据、模型的拟合数据以及未来的预测数据呈现在一张图上,是评估模型效果和展示成果最直观的方式。ggplot2 提供了强大的自定义绘图功能,能够将结果清晰地可视化。
最终的图表会清晰地展示历史数据的轨迹、模型在历史数据上的拟合情况,以及向未来延伸的预测曲线和其置信区间。
五、实操及优化记录
因为最终目标是要导入到网站中动态显示,所以除了执行分析和plot绘图之外,使之持续加工生成json数据也是重要一环。
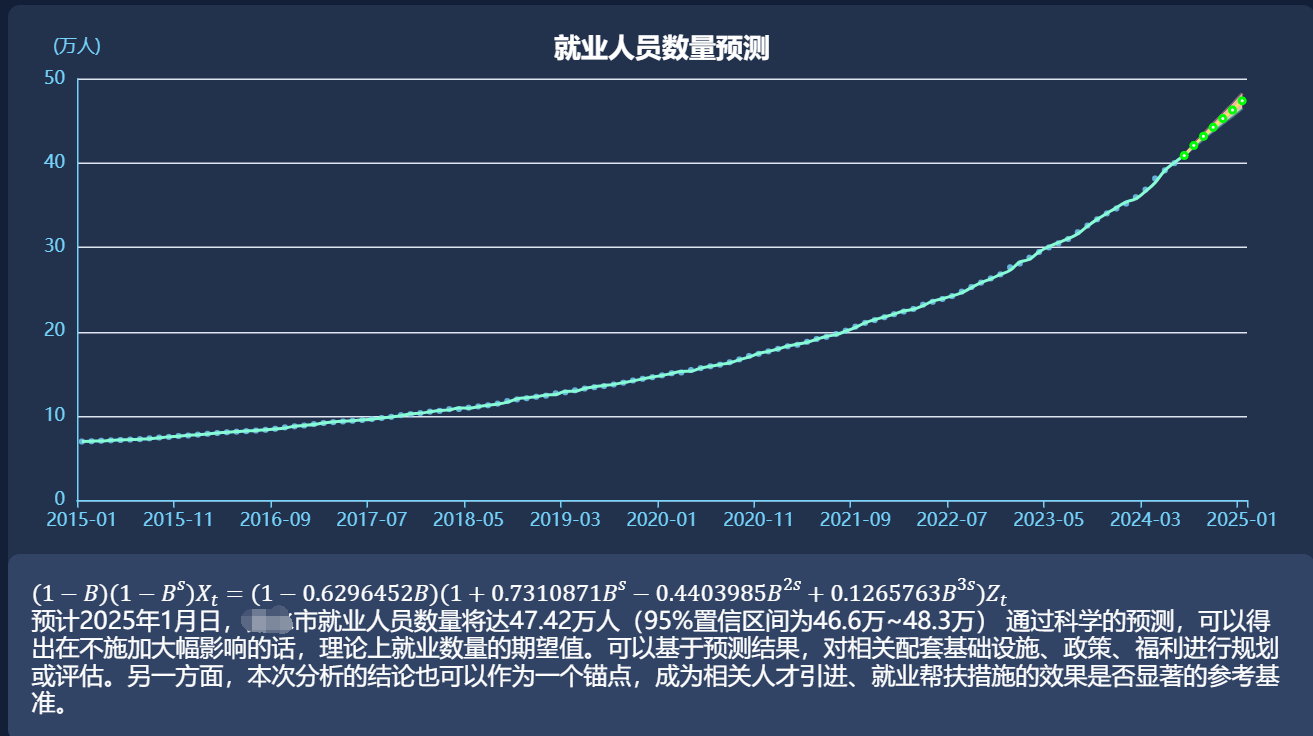
1.就业人员数量预测
ctrl+L 清控制台
# 清空数据
rm(list = ls())
# 设置工作空间
setwd("D:/zdream/数据分析/营商环境分析/00.数据分析过程文档/人才分析/r_bench")
# 导入数据
data <- read.csv("日期-人员-待拟合-1.csv", header = TRUE)
# 将数据时间序列化
ts_data <- ts(data$就业人数, start = c(2015, 1), frequency = 12)
# 拟合模型
library(forecast)
arima_model <- auto.arima(ts_data)
# 预测6个月数据
forecast_result <- forecast(arima_model, h = 6)
# 画基础数据点
plot(ts_data, main="就业人口信息数据及模型预测",
xlab="时间", ylab="就业人数(万人)", type="p", pch=20,
xlim=c(2015, 2025) ,
ylim=c(0, 40)
)
# 添加网格
grid()
# 合并拟合模型和预测数据
combined_ts <- ts(c(fitted(arima_model), forecast_result$mean),
start=tsp(fitted(arima_model))[1],
frequency=tsp(fitted(arima_model))[3])
# 画拟合模型与预测线
lines(combined_ts, col="purple", lwd = 3)
# 画预测点
points(time(forecast_result$mean), forecast_result$mean, col='red', pch=18)
# 添加图例
legend("topleft",
legend=c("原始数据","预测数据", "拟合模型"),
col=c("black","red","purple"),
lty=c("solid","solid","solid"),
lwd=c(NA,NA,3), pch=c(20,18,NA)
)
# 输出预测数据
print(forecast_result)
Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
Aug 2024 421125.8 419972.3 422279.4 419361.6 422890.0
Sep 2024 432067.8 430110.9 434024.8 429075.0 435060.7
Oct 2024 442761.3 439957.4 445565.2 438473.1 447049.4
Nov 2024 453183.1 449469.3 456896.9 447503.3 458862.9
Dec 2024 463248.4 458559.4 467937.4 456077.2 470419.6
Jan 2025 474219.3 468491.3 479947.2 465459.1 482979.4拟合模型数据导出
# 获取拟合值和时间点
fitted_values <- fitted(arima_model)
time_stamps <- time(fitted_values)
#定义时间序列时间戳到年月的转换函数
convert_to_year_month <- function(time_stamp) {
year <- floor(time_stamp)
month <- round((time_stamp - year) * 12) + 1
return(sprintf("%d-%02d", year, month))
}
# 格式化年月
year_month_stamps <- sapply(time_stamps, convert_to_year_month)
# 将年月和拟合值添加到结果数据框中
fitted_df <- data.frame(
年月 = year_month_stamps,
拟合值 = as.numeric(fitted_values)
)
简化之后:
# 定义时间序列时间戳到年月的转换函数
convert_to_year_month <- function(time_stamp) {
year <- floor(time_stamp)
month <- round((time_stamp - year) * 12) + 1
return(sprintf("%d-%02d", year, month))
}
# 获取、格式化年月、将年月和拟合值添加到数据框中
fitted_df <- data.frame(
年月 = sapply(time(fitted_values), convert_to_year_month),
拟合值 = as.numeric(fitted(arima_model))
)
# 将JSON数据保存到文件中
jsonlite::write_json(fitted_df[c("年月", "拟合值")], path = "D:/逐梦未来/数据分析/营商环境分析/00.数据分析过程文档/人才分析/r_bench/fitted_data.json", pretty = FALSE)原始数据导出
# 处理原始数据data,格式化日期
data$格式日期 <- as.Date(data$日期, format="%Y年%m月%d日")
# 提取年月
data$年_月 <- format(data$格式日期, "%Y-%m")
# 转换为JSON格式并导出到文件
jsonlite::write_json(data[c("年_月", "就业人数")], path = "D:/逐梦未来/数据分析/营商环境分析/00.数据分析过程文档/人才分析/r_bench/raw_data.json", pretty = FALSE)换一个方法导出原始数据
# 获取、格式化年月、将年月和原始数据添加到数据框中
raw_df <- data.frame(
年月 = sapply(time(ts_data), convert_to_year_month),
原始数据 = as.numeric(ts_data)
)
# 转换为JSON格式并导出到文件
jsonlite::write_json(raw_df[c("年月", "原始数据")], path = "D:/逐梦未来/数据分析/营商环境分析/00.数据分析过程文档/人才分析/r_bench/raw_data.json", pretty = FALSE)预测数据导出
提取和保存预测数据
# 提取预测点的数据
forecast_mean_values <- forecast_result$mean # 预测均值
forecast_lower_values <- forecast_result$lower[, 2] # 95%置信区间的下限
forecast_upper_values <- forecast_result$upper[, 2] # 95%置信区间的上限
# 提取均值时间点并转化为年月
forecast_time_points <-time(forecast_result$mean)
forecast_year_month_stamps <- sapply(forecast_time_points, convert_to_year_month)
# 保存到数据框
forecast_df <- data.frame(
年月 = forecast_year_month_stamps,
预测值 = forecast_mean_values,
下限 = forecast_lower_values,
上限 = forecast_upper_values
)上面这部分操作可以合并成以下代码
# 提取、转换、保存数据到数据框
forecast_df <- data.frame(
年月 = sapply(time(forecast_result$mean), convert_to_year_month),
预测值 = forecast_result$mean,
下限 = forecast_result$lower[, 2],
上限 = forecast_result$upper[, 2]
)
# 提取模型数据框(fitted_df)最新一个月的值
latest_month_fitted_data <- fitted_df[which.max(as.Date(fitted_df$年月, format="%Y-%m")), ]
# 获取模型数据框(fitted_df)最新一个月(最后一行数据)的值
latest_month_fitted_data <- data.frame(
年月 = fitted_df[nrow(fitted_df), "年月"],
预测值 = fitted_df[nrow(fitted_df), "拟合值"],
上限 = fitted_df[nrow(fitted_df), "拟合值"],
下限 = fitted_df[nrow(fitted_df), "拟合值"]
)
# 合并数据框
forecast_df_plus <- rbind(latest_month_fitted_data, forecast_df)
# 转换为JSON格式并导出到文件
jsonlite::write_json(forecast_df_plus[c("年月", "预测值","下限","上限")], path = "D:/逐梦未来/数据分析/营商环境分析/00.数据分析过程文档/人才分析/r_bench/forecast_data.json", pretty = FALSE)2.目录数据线性回归分析(非时间序列)
library(ggplot2)
data<-data.frame(
月份=c("2022-01","2022-02","2022-03","2022-04","2022-05","2022-06","2022-07","2022-08","2022-09","2022-10","2022-11","2022-12","2023-01","2023-02","2023-03","2023-04","2023-05","2023-06","2023-07","2023-08","2023-09","2023-10","2023-11","2023-12"),
累计量=c(15517,16076,16612,17401,17918,18459,18701,19388,19923,20460,21146,21993,22117,22300,22637,22963,23314,23639,24046,24715,25111,25275,25740,25982)
)
data$月份序号 <- as.numeric(factor(data$月份))
# 执行线性回归分析
model <- lm(累计量 ~ 月份序号, data = data)
summary(model)
# 绘制图表
ggplot(data, aes(x = 月份序号, y = 累计量)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE, color = "red", linetype = "solid") + #趋势线
scale_x_continuous(breaks = data$月份序号, labels = data$月份) +
labs(title = "全市目录量趋势V2", x = "月份", y = "累计量") +
theme_minimal() +
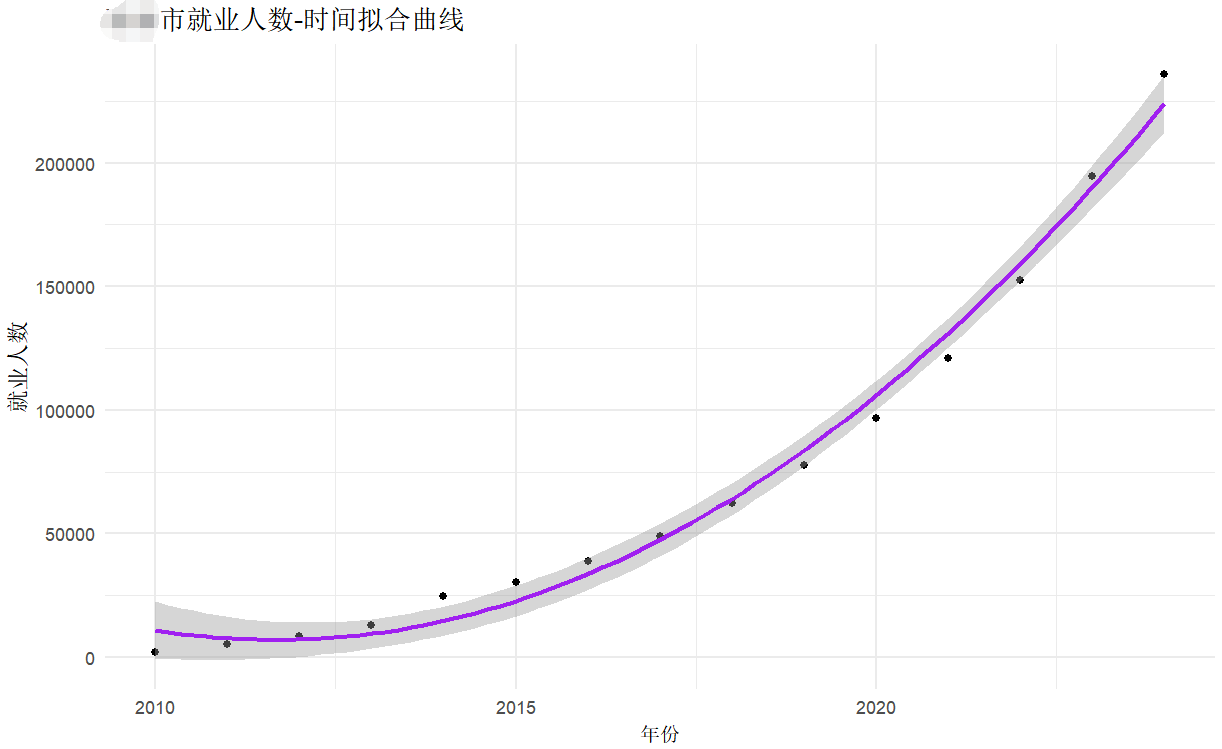
theme(panel.grid.major = element_line(color = "grey", linetype = "dotted")) 3.未采用时间序列分析的错误样例
这是某一次试验性分析时输出的结果,没有采用时间序列,单纯使用线性回归进行拟合,可以看到实际上偏离情况还是蛮严重的。
参考
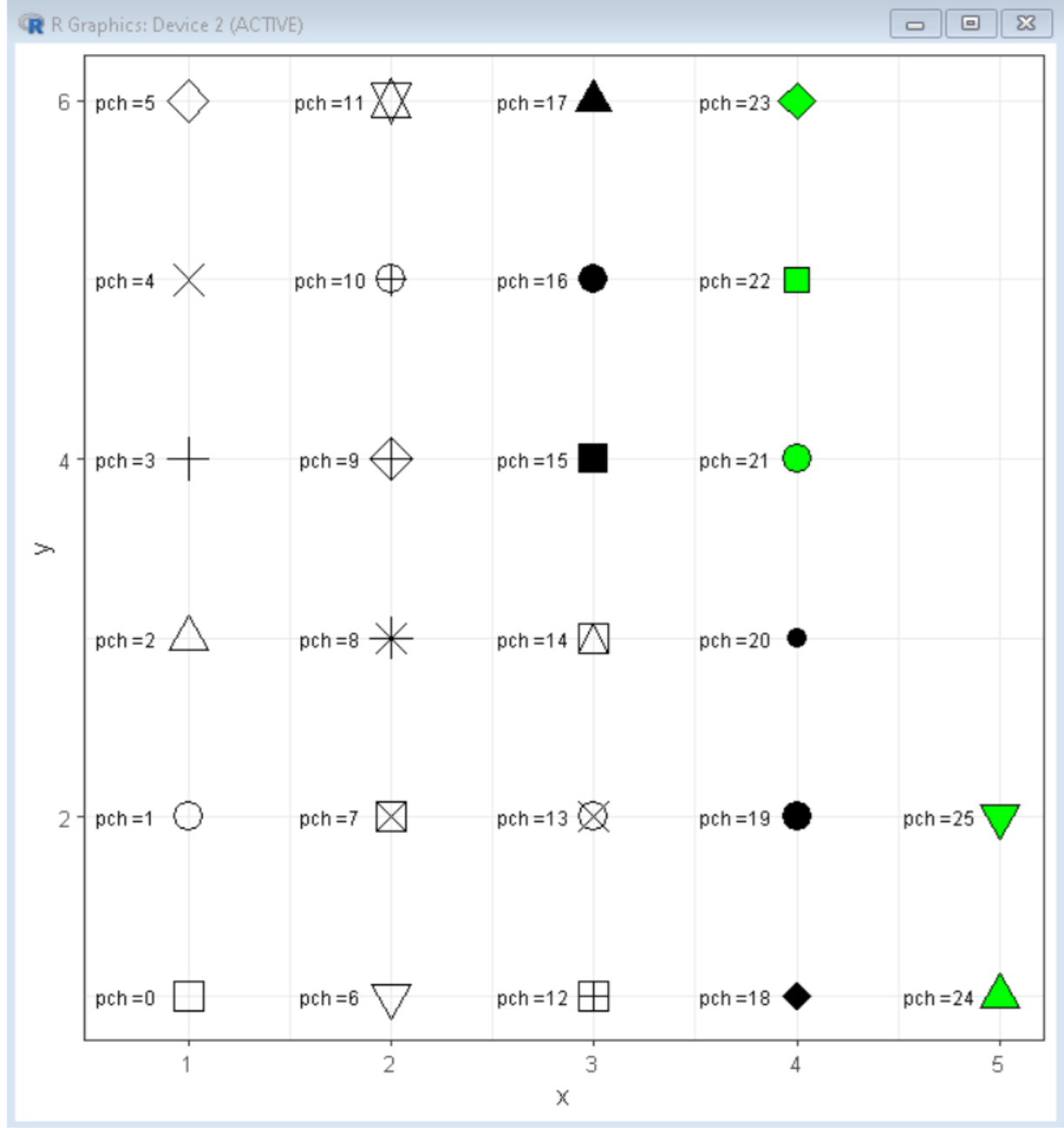
plot绘图函数
pch
pch(plotting character)
指定绘制点时使用的符号
type
"p":表示仅绘制数据点(默认的点图)。"l":表示通过线连接数据点(线图)。"b":同时绘制数据点和线(点线图)。"c":仅绘制线,不显示数据点。"o":同时绘制数据点和线,但线会覆盖在点上(与"b"类似,但线的绘制方式略有不同)。"h":绘制垂直的线段从点到x轴(也叫作悬挂图或针状图)。"s":绘制阶梯图。"n":不绘制任何点和线(通常用于初始化一个图形设备,以便后续添加内容)。
评论区