ZDREAM - Thassarian 的个人博客
对抗变化的方法唯有拥抱变化。
目 录CONTENT
以下是
学习笔记
相关的文章
-
 针对网站的用户行为分析:Matomo本地部署及踩坑记录 一、前言作为一个长期和数据打交道的人,我对各类数据指标有着近乎本能的关注。在维护自己的这个小网站时,很自然地就想到了要引入一套用户行为分析工具。它不仅能满足我个人的好奇心,了解一下都有谁、在什么时间、通过什么方式访问了这里,长期来看,这些数据的沉淀也能为网站内容的优化方向提供一些客观的参考。市面上的选择很多,比如强大的 Google Analytics。但在当前环境下,我更倾向于一个能将数据完全保留在自己服务器上的解决方案。这不仅是为了彻底的“数据私有”,也是出于一种技术上的“掌控感”。经过一番调研,开源的 Matomo 进入了我的视野。它功能全面,社区活跃,最关键的是,它支持完全本地化部署。为什么是 Matomo?在正式开始部署前,简单梳理一下选择 Matomo 的几个核心理由:数据所有权: 这是最重要的一点。所有访客数据都存储在自己的数据库里,不必担心隐私泄露或数据被用于其他目的。对于一些只在内网访问的政务系统,这种方案更是刚需。功能完备: 从实时访客、行为路径,到流量来源、设备统计,乃至转化漏斗分析,社区版的功能已经足够强大,完全可以满足个人网站和中小型项目的分析需求。开源免费: 无需承担额外的服务费用,只需要投入服务器资源和一些折腾的时间。良好的兼容性: 除了常规的网站,它同样支持对 APP、小程序甚至 IoT 设备的数据进行追踪,扩展性很好。二、部署体验1.平台部署和现在大多数应用一样,Matomo 的部署首选方案自然是 Docker。官方提供了相当完善的 Docker 镜像和部署指南,这让初始启动变得非常简单。我个人习惯使用 docker-compose 来编排容器,这样能更清晰地管理服务和数据卷。 一个基础的 docker-compose.yml 文件大概是下面这样,包含 Matomo 应用本身和一个独立的数据库服务。详细配置参考:https://github.com/matomo-org/docker/blob/master/.examples/nginx/compose.yml启动命令:docker run --rm --volumes-from="matomo-app-1" --link matomo-app-1 python:3-alpine python /var/www/html/misc/log-analytics/import_logs.py --url=http://ip.of.your.matomo.example --login=yourlogin --password=yourpassword --idsite=1 --recorders=4 /var/www/html/logs/access.log2.踩坑看似简单的部署,很快就遇到了第一个门槛:SSL 配置。Matomo 在初始化安装完成后,会强制要求使用 HTTPS 访问。这本身是一个非常合理的安全设定,但问题在于,官方的 Docker 镜像中,默认的 Apache 服务并未开启 SSL 模块。这就导致了一个矛盾:如果我在 docker-compose 里直接将容器的 443 端口映射出来并配置好域名,Matomo 在首次启动时会因为自身 Apache 不支持 SSL 而启动失败。这是一个典型的“先有鸡还是先有蛋”的问题。正确的解决思路是分两步走: 1. 先以 HTTP 方式完成 Matomo 的初始化安装。 2. 进入容器内部,手动为 Apache 配置 SSL,然后再将服务切换到 HTTPS。具体的步骤记录如下: #第一步:进入正在运行的 Matomo 容器。 bash docker exec -it matomo bash #第二步:在容器内为 Apache 启用 SSL 模块并重启服务。 a2enmod ssl service apache2 restart #第三步:修改 Matomo 的站点配置文件,添加 HTTPS 监听和证书配置。 nano matomo:/var/www/html/config/config.ini.php #添加https监听 <VirtualHost *:443> ServerName your.domain.com SSLEngine on SSLCertificateFile /etc/ssl/certs/fullchain.pem SSLCertificateKeyFile /etc/ssl/certs/privkey.pem </VirtualHost> #第四步:再次重启容器中的apache docker exec -it matomo service apache2 restart每次容器升级时(apache爆出的漏洞有点多,不升级不放心),证书问题都要重新处理一遍。3.网站接入部署完成后,剩下的工作就简单了。Matomo 会提供一段 JavaScript 追踪代码,只需要将它嵌入到网站所有页面的 <head> 标签里即可,比如说Halo的代码注入全局标签:对于使用 Vue 这类前端框架构建的单页面应用(SPA),虽然直接添加到index.html就能够实现访客IP时间等记录,但是无法区分出来用户具体访问了哪些页面,如果想详细的页面浏览情况分析,就需要额外配置路由切换时的页面追踪,官方文档中也有相应的说明:https://matomo.org/faq/new-to-piwik/how-do-i-install-the-matomo-tracking-code-on-websites-that-use-vue-js/?mtm_campaign=Matomo_App&mtm_source=Matomo_App_OnPremise&mtm_medium=App.CoreAdminHome.trackingCodeGenerator4.查看效果数据开始汇入后,Matomo 的仪表盘就变得鲜活起来。默认的仪表盘提供了丰富的信息模块,可以直观地看到实时的访客数量、访客的地理位置分布、访问趋势图、流量来源渠道、用户使用的操作系统和浏览器等。默认情况下,为了保护访客隐私,IP 地址是做了脱敏处理的,当然这个也可以根据需要进行修改。 通过这些数据,我可以清晰地看到哪些文章更受欢迎,访客是通过搜索引擎还是直接链接访问过来的。这些看似简单的信息,背后却能反映出很多问题,对于后续内容的调整和网站的优化,无疑是很有价值的。如果vue项目不针对性设置的话就会出现图里这种所有人只访问了/index的情况 ↑可以查看详细日志,默认是IP脱敏的,可以配置取消掉。总的来说,Matomo 的部署虽然比使用第三方 SaaS 服务要复杂一些,但整个过程完全在可控范围内。它最终交付给我的是一个完全私有、功能强大的网站分析平台,这种“拥有感”是任何第三方服务都无法替代的。 对于注重数据隐私的个人站长,或是需要对内部系统进行用户行为追踪的中小型项目来说,Matomo 无疑是一个值得投入时间去配置和使用的工具。它不仅是一个工具,其部署和配置的过程,本身也是一次不错的技术实践。
针对网站的用户行为分析:Matomo本地部署及踩坑记录 一、前言作为一个长期和数据打交道的人,我对各类数据指标有着近乎本能的关注。在维护自己的这个小网站时,很自然地就想到了要引入一套用户行为分析工具。它不仅能满足我个人的好奇心,了解一下都有谁、在什么时间、通过什么方式访问了这里,长期来看,这些数据的沉淀也能为网站内容的优化方向提供一些客观的参考。市面上的选择很多,比如强大的 Google Analytics。但在当前环境下,我更倾向于一个能将数据完全保留在自己服务器上的解决方案。这不仅是为了彻底的“数据私有”,也是出于一种技术上的“掌控感”。经过一番调研,开源的 Matomo 进入了我的视野。它功能全面,社区活跃,最关键的是,它支持完全本地化部署。为什么是 Matomo?在正式开始部署前,简单梳理一下选择 Matomo 的几个核心理由:数据所有权: 这是最重要的一点。所有访客数据都存储在自己的数据库里,不必担心隐私泄露或数据被用于其他目的。对于一些只在内网访问的政务系统,这种方案更是刚需。功能完备: 从实时访客、行为路径,到流量来源、设备统计,乃至转化漏斗分析,社区版的功能已经足够强大,完全可以满足个人网站和中小型项目的分析需求。开源免费: 无需承担额外的服务费用,只需要投入服务器资源和一些折腾的时间。良好的兼容性: 除了常规的网站,它同样支持对 APP、小程序甚至 IoT 设备的数据进行追踪,扩展性很好。二、部署体验1.平台部署和现在大多数应用一样,Matomo 的部署首选方案自然是 Docker。官方提供了相当完善的 Docker 镜像和部署指南,这让初始启动变得非常简单。我个人习惯使用 docker-compose 来编排容器,这样能更清晰地管理服务和数据卷。 一个基础的 docker-compose.yml 文件大概是下面这样,包含 Matomo 应用本身和一个独立的数据库服务。详细配置参考:https://github.com/matomo-org/docker/blob/master/.examples/nginx/compose.yml启动命令:docker run --rm --volumes-from="matomo-app-1" --link matomo-app-1 python:3-alpine python /var/www/html/misc/log-analytics/import_logs.py --url=http://ip.of.your.matomo.example --login=yourlogin --password=yourpassword --idsite=1 --recorders=4 /var/www/html/logs/access.log2.踩坑看似简单的部署,很快就遇到了第一个门槛:SSL 配置。Matomo 在初始化安装完成后,会强制要求使用 HTTPS 访问。这本身是一个非常合理的安全设定,但问题在于,官方的 Docker 镜像中,默认的 Apache 服务并未开启 SSL 模块。这就导致了一个矛盾:如果我在 docker-compose 里直接将容器的 443 端口映射出来并配置好域名,Matomo 在首次启动时会因为自身 Apache 不支持 SSL 而启动失败。这是一个典型的“先有鸡还是先有蛋”的问题。正确的解决思路是分两步走: 1. 先以 HTTP 方式完成 Matomo 的初始化安装。 2. 进入容器内部,手动为 Apache 配置 SSL,然后再将服务切换到 HTTPS。具体的步骤记录如下: #第一步:进入正在运行的 Matomo 容器。 bash docker exec -it matomo bash #第二步:在容器内为 Apache 启用 SSL 模块并重启服务。 a2enmod ssl service apache2 restart #第三步:修改 Matomo 的站点配置文件,添加 HTTPS 监听和证书配置。 nano matomo:/var/www/html/config/config.ini.php #添加https监听 <VirtualHost *:443> ServerName your.domain.com SSLEngine on SSLCertificateFile /etc/ssl/certs/fullchain.pem SSLCertificateKeyFile /etc/ssl/certs/privkey.pem </VirtualHost> #第四步:再次重启容器中的apache docker exec -it matomo service apache2 restart每次容器升级时(apache爆出的漏洞有点多,不升级不放心),证书问题都要重新处理一遍。3.网站接入部署完成后,剩下的工作就简单了。Matomo 会提供一段 JavaScript 追踪代码,只需要将它嵌入到网站所有页面的 <head> 标签里即可,比如说Halo的代码注入全局标签:对于使用 Vue 这类前端框架构建的单页面应用(SPA),虽然直接添加到index.html就能够实现访客IP时间等记录,但是无法区分出来用户具体访问了哪些页面,如果想详细的页面浏览情况分析,就需要额外配置路由切换时的页面追踪,官方文档中也有相应的说明:https://matomo.org/faq/new-to-piwik/how-do-i-install-the-matomo-tracking-code-on-websites-that-use-vue-js/?mtm_campaign=Matomo_App&mtm_source=Matomo_App_OnPremise&mtm_medium=App.CoreAdminHome.trackingCodeGenerator4.查看效果数据开始汇入后,Matomo 的仪表盘就变得鲜活起来。默认的仪表盘提供了丰富的信息模块,可以直观地看到实时的访客数量、访客的地理位置分布、访问趋势图、流量来源渠道、用户使用的操作系统和浏览器等。默认情况下,为了保护访客隐私,IP 地址是做了脱敏处理的,当然这个也可以根据需要进行修改。 通过这些数据,我可以清晰地看到哪些文章更受欢迎,访客是通过搜索引擎还是直接链接访问过来的。这些看似简单的信息,背后却能反映出很多问题,对于后续内容的调整和网站的优化,无疑是很有价值的。如果vue项目不针对性设置的话就会出现图里这种所有人只访问了/index的情况 ↑可以查看详细日志,默认是IP脱敏的,可以配置取消掉。总的来说,Matomo 的部署虽然比使用第三方 SaaS 服务要复杂一些,但整个过程完全在可控范围内。它最终交付给我的是一个完全私有、功能强大的网站分析平台,这种“拥有感”是任何第三方服务都无法替代的。 对于注重数据隐私的个人站长,或是需要对内部系统进行用户行为追踪的中小型项目来说,Matomo 无疑是一个值得投入时间去配置和使用的工具。它不仅是一个工具,其部署和配置的过程,本身也是一次不错的技术实践。 -
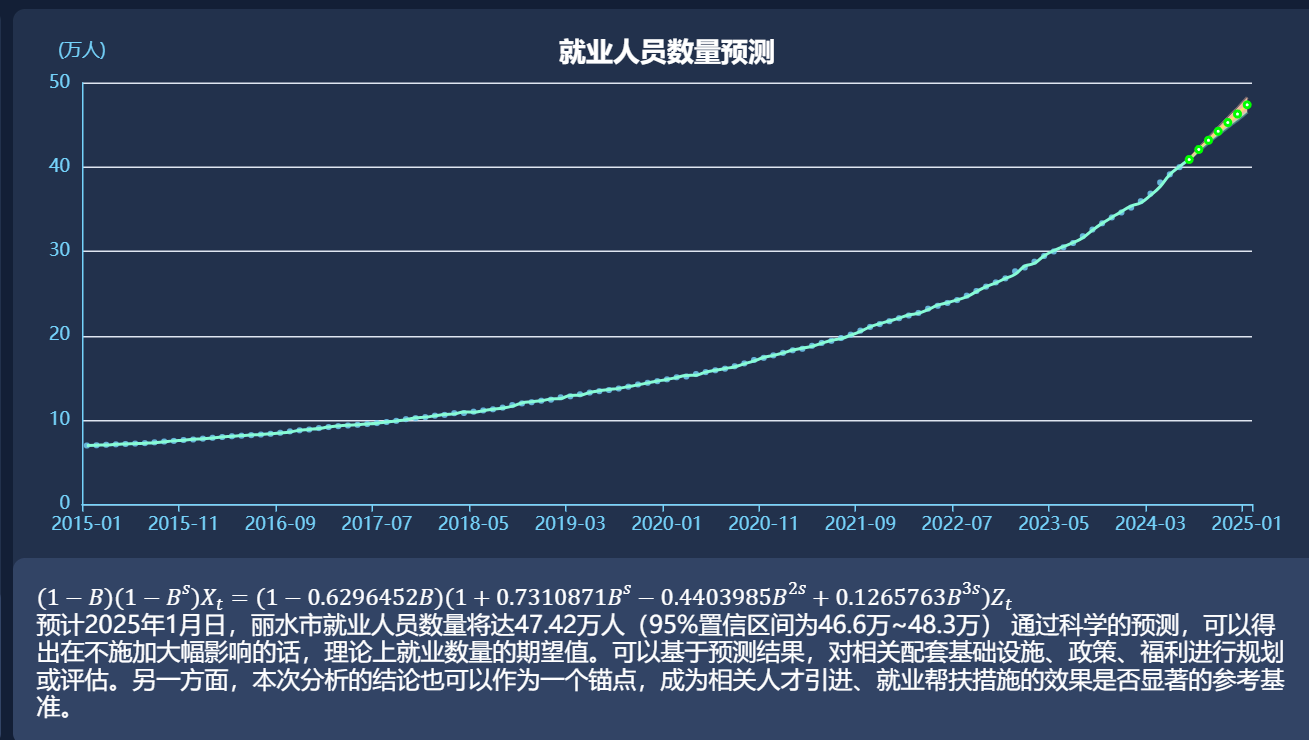
预测未来:基于历史数据的时间序列拟合分析 最终效果在数据处理的日常工作中,我们常常会面对历史数据,并期望能从中洞察未来的趋势。无论是业务量的变化、用户增长的预测,还是像特定领域人才流动的预判,其核心都是一个基于时间的序列。这篇笔记整理了过去一次探索性的尝试,即如何利用R语言对时间序列数据进行拟合与预测,整个过程本身比最终的结论更有记录的价值。 当时设想的场景,是根据过去数年的人才流入数据,来预测未来一段时间的流入趋势。这是一种典型的单变量时间序列分析。核心思路是让机器通过学习历史数据的内在规律——包括长期趋势(Trend)、季节性波动(Seasonal)和随机噪声(Random),来构建一个能够延伸到未来的数学模型。一、数据准备与加载 一切分析始于数据。首先需要将原始数据加载到R环境中,并转化为时间序列分析专用的格式。原始数据通常包含日期和数值两个关键字段。这里使用了 lubridate 包来高效处理日期格式,并用 ts 函数创建一个时间序列对象,明确告知R数据的观测频率(在这个案例中是按月,即frequency=12)。将数据结构化为 ts 对象,是后续所有分析步骤的标准起点。二、序列分解 拿到一个时间序列后,直接建模往往效果不佳,因为它是一个混合体。将其分解,分别观察长期趋势、季节性规律和随机波动,能更好地理解数据特性。R中的 decompose() 函数可以很方便地完成这项工作,它将序列拆解为三个部分。趋势(Trend):数据在长期内的总体走向,是上升、下降还是保持平稳。季节性(Seasonal):数据在一个固定周期内(如年、季度)呈现的规律性波动。随机项(Random):剔除趋势和季节性后,剩余的、无规律的随机扰动。通过分解图,可以直观地判断该序列是否具有明显的趋势性和季节性,为后续选择模型提供依据。三、模型选择与拟合 时间序列预测最常用的模型之一是ARIMA(自回归积分滑动平均模型)。ARIMA的强大之处在于它能处理多种不同类型的时间序列数据,但其p, d, q三个参数的选择却非常考验经验。 幸运的是,forecast 包中的 auto.arima() 函数极大地简化了这一过程。它会自动测试不同的参数组合,通过AIC(赤池信息准则)或BIC(贝叶斯信息准则)等评估标准,寻找最优的模型。这对于快速验证想法非常友好,避免了在调参上投入过多初期精力。summary 会输出最终选定的ARIMA模型参数和一些关键的统计指标,如对数似然、AIC值等,用于评估模型的优劣。四、预测与可视化 模型构建完成后,就可以用它来生成对未来的预测了。forecast() 函数接收拟合好的模型,并指定需要预测的期数(例如h=12代表预测未来12个月)。它不仅会给出预测值,还会提供置信区间(如80%和95%),这在实际应用中非常重要,因为它量化了预测的不确定性。 最后,将原始数据、模型的拟合数据以及未来的预测数据呈现在一张图上,是评估模型效果和展示成果最直观的方式。ggplot2 提供了强大的自定义绘图功能,能够将结果清晰地可视化。最终的图表会清晰地展示历史数据的轨迹、模型在历史数据上的拟合情况,以及向未来延伸的预测曲线和其置信区间。五、实操及优化记录因为最终目标是要导入到网站中动态显示,所以除了执行分析和plot绘图之外,使之持续加工生成json数据也是重要一环。1.就业人员数量预测ctrl+L 清控制台 # 清空数据 Jan 2025 474219.3 468491.3 479947.2 465459.1 482979.4拟合模型数据导出 # 获取拟合值和时间点 简化之后: # 定义时间序列时间戳到年月的转换函数 jsonlite::write_json(fitted_df[c("年月", "拟合值")], path = "D:/逐梦未来/数据分析/营商环境分析/00.数据分析过程文档/人才分析/r_bench/fitted_data.json", pretty = FALSE)原始数据导出 # 处理原始数据data,格式化日期 jsonlite::write_json(data[c("年_月", "就业人数")], path = "D:/逐梦未来/数据分析/营商环境分析/00.数据分析过程文档/人才分析/r_bench/raw_data.json", pretty = FALSE)换一个方法导出原始数据 # 获取、格式化年月、将年月和原始数据添加到数据框中 jsonlite::write_json(raw_df[c("年月", "原始数据")], path = "D:/逐梦未来/数据分析/营商环境分析/00.数据分析过程文档/人才分析/r_bench/raw_data.json", pretty = FALSE)预测数据导出提取和保存预测数据 # 提取预测点的数据 )上面这部分操作可以合并成以下代码 # 提取、转换、保存数据到数据框 jsonlite::write_json(forecast_df_plus[c("年月", "预测值","下限","上限")], path = "D:/逐梦未来/数据分析/营商环境分析/00.数据分析过程文档/人才分析/r_bench/forecast_data.json", pretty = FALSE)2.目录数据线性回归分析(非时间序列) library(ggplot2) theme(panel.grid.major = element_line(color = "grey", linetype = "dotted")) 3.未采用时间序列分析的错误样例这是某一次试验性分析时输出的结果,没有采用时间序列,单纯使用线性回归进行拟合,可以看到实际上偏离情况还是蛮严重的。 参考plot绘图函数pchpch(plotting character)指定绘制点时使用的符号type"p":表示仅绘制数据点(默认的点图)。"l":表示通过线连接数据点(线图)。"b":同时绘制数据点和线(点线图)。"c":仅绘制线,不显示数据点。"o":同时绘制数据点和线,但线会覆盖在点上(与"b"类似,但线的绘制方式略有不同)。"h":绘制垂直的线段从点到x轴(也叫作悬挂图或针状图)。"s":绘制阶梯图。"n":不绘制任何点和线(通常用于初始化一个图形设备,以便后续添加内容)。
-
-
-
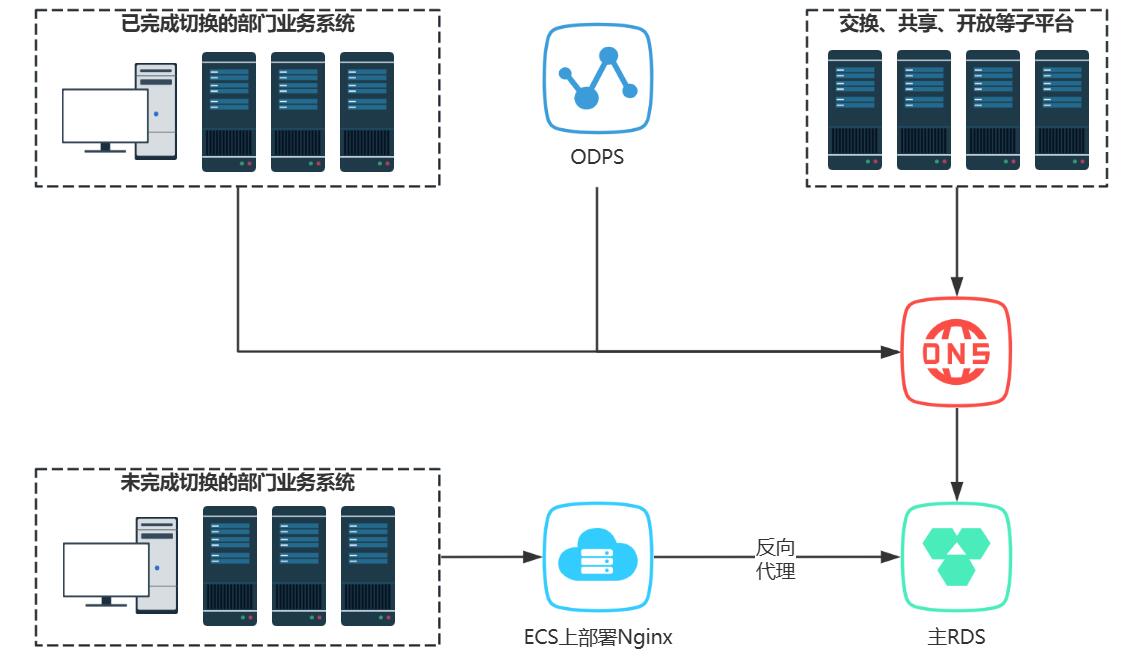
自建数据库平滑迁移RDS+异云容灾 平台业务开展前期,我司团队在Windows系统的ECS服务器上部署了MySQL服务,因版本升级不及时、同一服务器会同时用于人工操作其他业务导致存在安全隐患,需要切换为由云平台统一管理的RDS,同时为保障业务的高可用,应客户要求推进异云容灾工作。一、核心需求将数据从ECS服务器上的自建MySQL,迁移至移动云RDS。接入电信云作为备库,实现异云容灾。在预期部门无法及时配合切换的情况下,确保平滑迁移不影响业务数据流转。二、技术方案1、前期梳理事实上目前为止前置库的管理一直比较混乱,明确各个数据库及帐号的归属、梳理账号权限和白名单设置情况也是本项目的任务之一。2、准备阶段此阶段的核心目标是在不影响现有业务的前提下,建立数据同步链路。部署新库: 准备一个新的主RDS实例作为迁移目标。数据同步: 使用DTS (Data Transmission Service)工具,配置从现有ECS上部署的MySQL到新主RDS的单向增量数据同步。在此期间,所有业务系统(包括各部门业务系统和ODPS)的数据库连接保持不变,继续访问旧的MySQL。新RDS此时作为一个“影子库”,其实时性由DTS保证。3、平滑切换阶段考虑到不同业务系统的改造进度和依赖差异,切换过程需要分批次、平滑进行。直接切换: 对于可以修改配置的业务系统,将其数据库连接地址直接变更为新主RDS的域名。如图中“已完成切换的部门业务系统”。代理切换: 对于暂时无法修改配置,或尚未完成切换的业务,采用反向代理方案作为过渡。在原MySQL所在的ECS上部署Nginx,并配置TCP转发。这样,未切换的应用依然访问旧的IP地址,但请求会被Nginx透明地转发至新的主RDS。这个阶段,新旧两种连接方式并存,但所有数据库的实际读写都已经落在新的主RDS上。4、异云容灾与收尾在所有业务系统都完成切换,确认不再有流量走向Nginx代理后,即可进入收尾和容灾建设阶段。完成切换: 协调所有业务方(包括ODPS),确保其数据库连接均已改为直接访问主RDS域名。资源释放: 下线并释放用于Nginx代理的ECS资源。容灾建设:灾备云对等部署所有ECS和RDS节点。在主RDS和灾备RDS之间建立数据同步链路。通过DNS对数据库域名进行管理。当主节点发生故障时,可通过变更DNS解析将流量切换至灾备节点,实现容灾。三、进度计划略。四、沟通机制1.、组织架构数据局移动云电信云平台运维总集各子平台负责人数据运维总集数据归集、治理、共享、专题库运维业务各区县大数据中心部门数据专员2.、联系人清单略。3、问题通报、反馈机制五、质量及风险控制1、影响范围如果出现级故障,可能影响如果出现级故障,可能影响2、Nginx代理的风险第二阶段的Nginx代理是一个过渡方案,但也构成了一个单点。如果它在切换窗口期内故障,会影响未切换的业务。这里或许需要评估风险或准备备用方案(如Keepalived)。3、切换的RTO/RPO基于DNS的故障切换,需要考虑各地DNS缓存刷新延迟,这会直接影响RTO(恢复时间目标)。同时,主备RDS之间的数据同步链路延迟决定了RPO(恢复点目标)。这两个指标需要明确。六、附件1. 关联部门及联系人清单2. 各部门与前置库数据表对应关系明细3. 各前置库数据表使用明细确认表4. 需求确认单5. 实施方案确认表6. 部门参与计划确认表7. 部门完成改造确认单8. 数据核查记录表9. 业务核查表10. 验收确认单
-
-
-
-
网络问题排查的一些常用命令与思路 排查网络问题,本质上是一个由表及里、逐层排除的过程。比较稳妥的思路是:先点到点(ping) -> 再到端口(telnet) -> 再看路径(traceroute)。同时结合 服务端自查(netstat、curl),逐步缩小问题范围。如果问题指向中间网络,再深入到防火墙策略和路由规则。一、 客户端/终端侧排查第一步排查始于问题发生点,无论是开发人员的本地环境、用户的PC,还是发起API调用的另一台服务器,都可以视作“客户端”。1. ping最基础也最常用的命令,用于检查网络连接的基本可达性。它通过ICMP协议发送回声请求,测试目标主机是否在线以及网络延迟。ping 114.114.114.114看到类似 time=...ms TTL=... 的返回,说明至少在网络层面上,你的设备和目标服务器之间是连通的。如果超时(Timeout),则说明网络不通,或者对方禁用了ICMP协议(部分服务器会出于安全考虑关闭ping响应)。2. ipconfig / ifconfig用于查看本地网络配置。在采取任何行动前,先确认自己的网络配置是否正确。Windows: ipconfigLinux/macOS: ifconfig 或 ip addr主要关注点是本机IP地址、子网掩码和默认网关。有时候问题仅仅是本地IP配置错误或DHCP没有获取到正确地址。3. traceroute / tracert如果 ping 不通,或者延迟很高,可以用这个命令来探测数据包从源到目的地所经过的路由路径。Windows: tracertLinux: traceroutetracert www.example.com它会列出数据包经过的每一个路由器(“跳”)。如果在某一跳开始出现 * * * 或高延迟,问题很可能就出在那个节点或其后的链路上。这对于判断问题是出在内部网络、运营商网络还是目标网络非常有帮助。4. telnet / ncping 只能确认网络层(IP层)的可达性,但服务通常运行在传输层(TCP/UDP)的特定端口上。telnet 或 netcat(nc) 可以用来检查某个IP的特定端口是否开放和监听。# 检查目标服务器的8080端口是否开放 telnet 192.168.1.100 8080如果屏幕变黑或显示连接成功信息,说明端口是开放的,应用正在监听。如果提示“Connection refused”,说明服务器拒绝了连接,可能是服务未启动或防火墙拦截。如果长时间无响应,说明请求在中间某个环节被丢弃了,很可能是网络设备(如防火墙)拦截了。二、 服务端侧排查如果客户端到服务器的路由是通的,但服务依旧不可用(例如 telnet 端口不通),焦点就要转移到服务器本身。1. netstat / ss用于检查服务器自身的网络连接和监听状态。ss 是 netstat 的一个更快、更现代的替代品。# 查看所有监听的TCP端口 netstat -tulnp # 或者使用ss,并过滤特定端口(如8080) ss -tuln | grep 8080这个命令可以快速确认服务是否已成功启动并在预期的端口上进行监听。如果没有找到对应的端口,那问题就是应用本身没有启动成功。2. curl / wget在服务器本地测试服务是否正常。这可以排除外部网络因素,验证应用本身的功能。# 从服务器本地访问自己的web服务 curl http://127.0.0.1:8080/health如果本地访问正常,但远程访问失败,那么问题几乎可以锁定在服务器的防火墙、安全组策略或上游网络设备上。3. tcpdump这是一个强大的网络抓包工具,是网络问题排查的“大杀器”。当其他方法都无法定位问题时,可以用它来捕获流经网卡的原始数据包,分析最底层的通信细节。# 抓取80端口的TCP流量 tcpdump -i eth0 tcp port 80 -nn通过分析抓包结果,可以清晰地看到TCP三次握手是否成功、数据传输是否完整、是否有异常的RST包等。4. 查看日志最后但同样重要的一点,检查应用日志、中间件日志(如Nginx、Tomcat)和系统日志(/var/log/messages 或 journalctl)。很多时候,连接问题会在日志中留下明确的错误信息。三、 网络设备/网关侧当终端和服务端自查都正常,问题很可能出在中间的链路上,比如公司的防火墙、路由器、交换机,或者云平台的安全组。这个层面通常需要网络管理员或有相应权限的运维人员介入。1. 访问控制/防火墙规则检查防火墙(无论是硬件防火墙、iptables,还是云厂商的安全组/NACL)的策略。这是最常见的“中间”问题。核心检查点: 是否允许来自源IP(或IP段)的流量访问目标IP的特定端口和协议(TCP/UDP)。规则遵循“最小权限”原则,默认拒绝所有未明确允许的流量。2. 路由规则在复杂的网络环境中,路由器需要知道如何将数据包转发到正确的目的地。核心检查点: 检查路由表。确认是否存在到达目标网段的正确路由,是否存在路由黑洞或错误的下一跳。在路由器或交换机上,通常使用 show ip route 或 display ip routing-table 等命令查看。
-